

汉萨资讯About Us
首页 >汉萨资讯人工智能生成内容之法律问题分析
发布:admin 浏览:3057次
随着互联网和计算机技术的发展,使得人工智能系统(AI System)在今天逐渐开始成熟,具体表现为:伴随着大数据、芯片算力和AI算法的快速更新,使得人工智能系统越来越成熟,近几年出现像chatGPT、ChatGLM、BERT、StableDiffuison、Midjourney、DALL.E以及国内的阿里“通义千问”、百度的“百度文心一言 ”等这类成熟而优秀的人工智能产品,基于他们的应用也开始呈现呈现爆发式增长。今天的AI-System不但可以生成文字内容和图片,还可以生成各种视频和语音,可以用于作工业设计等,给市场带来空前的商机与活力。
但与此同时,由于人工智能的应用也带来一系列新的法律问题,这些问题往往在现有法律框架内无法有效解决,立法呈现滞后性,本文仅探讨其中三个此类问题:(1)训练使用的素质能否利用合理使用原则;(2)人工智能生成的内容能否适用知产法保护;(3)人工智能生成的内容如何保护。
一、人工智能系统训练与生成的本质
人工智能系统的核心技术是:机器学习。在机器(人工智能系统,属于计算机信息系统的一类)学习之后,便可以使用该人工智能系统进行内容生成,下面对此作详细解释。
(一)机器学习的原理
所谓机器学习是指:用户准备一些特定格式要求的数据,并将这些数据灌输给人工智能系统(AI System),令其对这些数据进行计算、分析、总结形成模型(Model)保存。这些模型是日后进行内容生成的基础和前提。机器学习有不同分类方法,例如下面就一种分类方法:
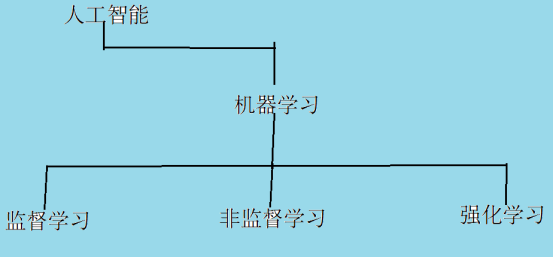
从人工智能专业化角度看,机器学习的本质是:让机器自动找一个函数,这个函数能满足用户的需求,如下所示:
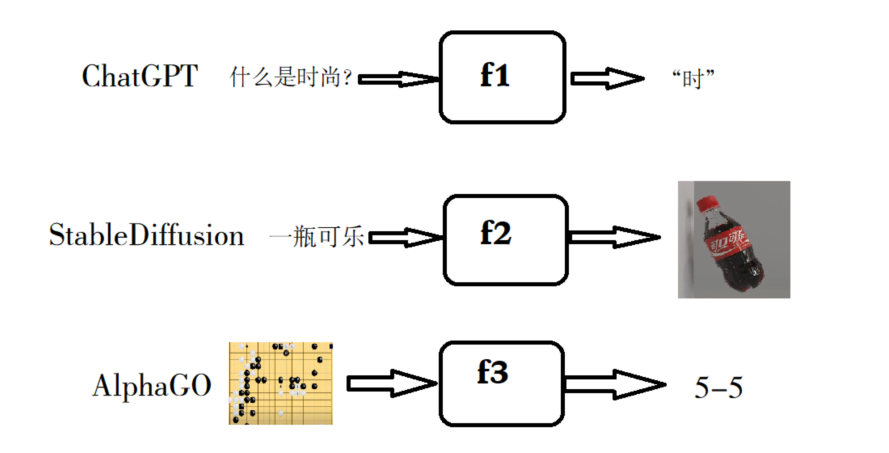
注意:上图中显示了三个不同功能的函数,左边是用户输入(Prompt),右边是函数输出(Structural Output,生成的内容)。
该图表明,如果用户需要聊天功能(chatGPT),则通过机器学习训练一个函数名为f1,这个函数接收用户的输入信息(用户的提问),产生输出信息(chatGPT给用户的答案);StableDiffusion是用于绘图的,函数名为f2,用户给这个函数输入一个值(一句话描述绘图要求),这个函数能按要求生成内容并输出(输出一张图片)。
当然,人工智能系统中用户要找这个函数显然不是普通的数学函数,它的候选集是特定的,比如各种神经网络算法(前馈神经网络/FNN、卷积神经网强/CNN、生成式对抗网络/GAN等 )、决策树(Decision-Tree)等 ,限于篇幅此处不作展开讨论,我们需要理解的是:机器学习中,这些要确定的函数都属于神经网络(广义,Neutral Network)算法,神经网络算法的特征是能够模拟人脑学习知识并存储知识,并再次生成内容。
故而是,人工智能系统不同于传统的搜索引擎(如传统的GOOGLE搜索、百度搜索、搜狗等 ),后者只是简单而机械的检索到信息,再把检索到的信息整块输出,它并不理解人类语言逻辑;而前者则具备一定程度理解人类语言逻辑的能力,它的输出不是把检索到的整块信息一交性输出 ,而是从神经网络各个不连续的存储节点中通过对比提取内容,逐字逐句的生成回答的信息(Structural Output),这个过程与人脑神经元记忆和回答的过程有些类似。
(二)人工智能系统(AI-System)的使用
尽管人工智能系统内部是一种集多种学科、专业中极度复杂理论的产物,但是从用户视角看,它就是一个计算机信息系统,在外观上表现为一套特定的计算机软件。而相应硬件的配置取决于要训练的模型(Model)大小。如果要巨大的模型,则需要较高的计算机硬件配置,比如可能需要多块英伟达的A100显卡,需要很多电费。本文仅从用户角度来分析人工智能系统的应用,以便看清它的原理,这样分析法律问题才能透彻而有根基,不至于空对空。
用户在拿到任何人工智能系统(安装配置好的计算机信息系统)后,具体要做以下两个步骤:第一步,训练(Training);第二步,使用(Using)。下面对这两个步骤的原则作简要说明,在说明过程中参照下图:
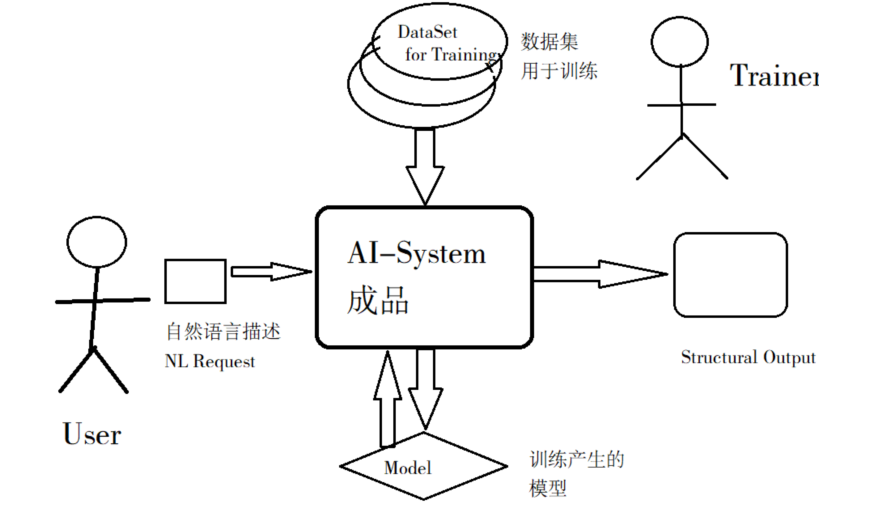
(1)训练(Training)
如上图,训练与机器学习是同一个事情的两个表达,表现为:训练者(Trainer)使用准备好的数据集(DataSet)输入给AI-System(训练),让其进行学习(计算、分析、总结)形成模型(Model),并存储模型到神经网络结构中(表现为特定结构的磁盘文件)。显然,用户的数据集越大,则模型可能越大,此即为“大模型”。当然,需要的硬件配置(尤其是GPU芯片)也越高,要花的电费也越多。比如,根据互联网上的信息,chatGPT仅运算一次要花费450万美元。
数据集的来源可以是多样的,典型的来源是从互联网用爬虫抓取并清洗数据。
须要注意的是:用户拿到AI-System通常进行了预训练(此时AI-System仅学习到一些基本的语言知识及常识性问题),用户仅需要进行所谓的“微调训练”(针对某一个领域的专业知识进行训练,通常要求使用专业化的、优质材料),这种训练可以是监督的也可以是非监督的(前者在训练材料上打标签,后者不打标签,让机器自己总结规律)
(2)使用(Using)
如上图,经过训练/机器学习后,AI-System生成了自己的模型(Model),此时便可以让机器进行内容生成了。通常的操作是:用户(User)使用人类语言描述一个请求(Natural Language Request,NLR)输入给AI-System,AI-System收到输入后,通过使用自己的模型中存储的知识结构来生成回答内容,并输出给用户。
以上两步是任何AI-System都适用的,笔者在撰写本文时,通过自己机器安装了一个缩微版的AI-System,名为nanoGPT,进行了训练(Training)和使用(输入指令提问题,让nanoGPT回答),该AI-System可以生成小模型,对用户的计算机配置要求不高,也不需要用户的计算机必须有英伟 达的GPU,完全支持使用CPU进行训练,它对于理解AI-System本身工作原理来说是一个非常好的工具。
二、两个关键法律问题分析
在了解AI-System的训练与使用后,本文探讨其中涉及的三个关键法律问题,具体如下:
(一)训练使用的素质能否利用合理使用原则(fair use)
训练AI-System时,须要有训练使用的数据集(上图中的DataSet),这些数据集的来源无非这么几个类型:(1)互联网爬爬取(2)人工制作(现场创作新的或是复制现有的)(3)内部数据授权(通常是单位的批量数据授权,也可能是个人)。以下是chatGPT训练使用的数据集占比:
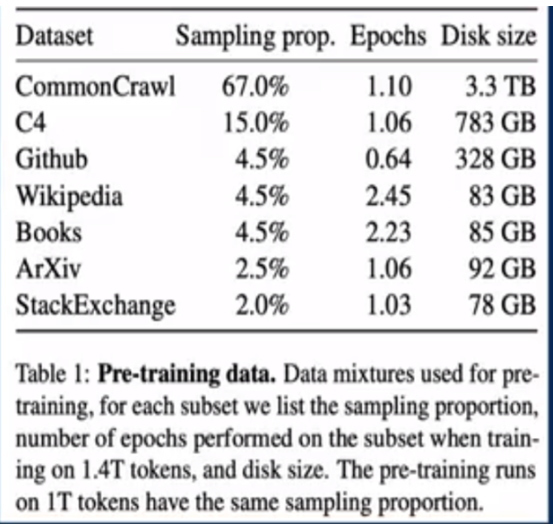
注意,其中有67.0%是爬虫从互联网上爬取的,来自书籍的占4.5%,来自论文网ArXiv占2.5%。
上述(1)和(2)来源的训练素材必定涉及侵犯他人的知识产权问题(可能是专利权或著作权),此处仅以著作权(版权)为例进行分析,具体分析AI-System对未经授权的他人材料是否可以“合理使用”
“合理使用原则 (fair use)”在国际法及各国国内关于知识产权立法基本上有规定。
国际方面:《保护文学和艺术作品伯尔尼公约》(《Berne Convention for the Protection of Literary and Artistic Works》)第九条第一款第二项中明示了合理使用原则,其内容为:“It shall be a matter for legislation in the countries of the Union to permit the reproduction of such works in certain special cases, provided that such reproduction does not conflict with a normal exploitation of the work and does not unreasonably prejudice the legitimate interests of the author.”。
国内法方面:(1)中国《著作权法》第二章第四节:著作权的限制,如:个人的学习、研究,执法公务,新闻报道、阅读障碍者使用等 ;(2)德国《著作权及邻接权法》(《Gesetz über Urheberrecht und verwandte Schutzrechte》,UrhG.)中第六章” Schranken des Urheberrechts durch gesetzlich erlaubte Nutzungen (译文:基于法律许可而对著作权的限制),其中规定 :Öffentliche Reden、Rechtspflege und öffentliche Sicherheit、Menschen mit einer Seh- oder Lesebehinderung;(3)《美国版权法》(Copyright Law of the United States)第107条“Limitations on exclusive rights: Fair use”,comment, news reporting, teaching (including multiple copies for classroom use), scholarship, or research。
合理使用原则,在有些内国法(如中国著、德国法)被称为“对著作权/版权的限制”,两者实际是一个概念,只是站在不同的主体角度,具体而言:站在版权人/著作权人角度是对其版权/著作权的合理限制(中国法及德国法),站在使用者角度就是合理使用(美国版权法)。
总结以上条款,发现:合理使用原则的特征,即:非赢利性,基于社会公益或非公益使用(如学习研究、个人欣赏),但是非赢利性是其统一内在本质,而相应的,著作权/版权的保护,其核心也恰恰在于保护作者使用作品进行独占性的赢利权利,以此来激发创作。
然而,如果将他人有版权的作品以某种技术手段(如互联网爬虫或扫描、键入纸制书籍)收集来免费使用,用来训练AI-System,生成了模型,这个模型显然是可以直接或间接用来赢利的,此时对于他人作品的使用,显然是基于“赢利目的”,不是非赢利目的,能否适用“合理使用原则 ”?依一般逻辑显然是不能的适用的。也就是说:基于训练AI-System之目的使而使用他人的作品,显然这是赢利目的,不能免费使用,必须取得版权人/著作权人授权,否则便是侵犯知识产权。
此处,我们可以从实质上分析对一下,自然人学习与机器学习的异同,以便理解为什么AI-System的训练材料不能适用“合理使用原则 ”。二者相同点是:都通过学习掌握了一些知识,未来都可以以这些知识为基础制作新的内容(作品或数据输出),都有神经网络存储特征,不同点例举如下:
第一,自然人的学习,是“受教育权”、“生存与发展权”等多项权利的集合效果,而作为AI-System的机器学习显然不是基于这些权利,作为AI-System的机器学习显然不享有这些权利。
第二,自然人的学习一定会受道德、伦理等社会因素及爱好等心理因素制约,而机器学习则无这些限制或约束,机器学习只是掌握材料的内在逻辑体系。
第三,自然人的学习属于非市场行为,而机器学习则是标准的市场行为,构成重要的商事活动,例如OpenAI的ChatGPT、阿里的通义千问、百度的文心一言等都是为了抢占市场赢利,这属于商事活动。
第四,自然人的学习基于单一人脑智力吸收,能充分体现了权利平等和公平竞争原则,故而,除非有重大发明创造等极少数情况,否则一个人的智力、知识一般不会造成个人的绝对优势,所以不存在个人垄断问题。而机器学习则不同,与自然人学习恰恰相反,谁拥有更多芯片算力、更多的数据集、更先进算法研发队伍,谁的AI-System将超越其它系统,独树一枝,进而形成垄断 ,因为芯片、数据、算法都是可以高度资本化操作的,而资本天生具有“集中化”、“垄断化”等特征和趋势,这反而会成造严重的不公平。
由此可见,对比之下,由于机器学习是少数人受益的商事行为,容易造成严重的机会不平等,并且可能突破伦理等社会规则的限制。我们可以据此得出结论:一方面,训练AI-System所使用的资料显然不能主张“合理使用原则”,无论基于著作权法/版权法等实体法规定还是基于社会公平正义这一基本观念考虑;但是另一方面,我们又不能否认AI-System对于市场发展、社会进步的积极作用。
故此,以ChatGPT的训练数据为例,显然,其训练数据中来自互联网爬虫的67%数据不适用“合理使用原则 ”,必须取得版权人/著作权人的授权。但是如果严格惯彻“取得授权”这个原则,那训练一个chatGPT仅授权费用这部分成本就难得做到,时间上空间上操作也是困难重重,如此便不可能出现chatGPT这种优秀产品。如何平衡二者,即“保护原著作权人/版权的权利(私益)”与“支持科技创新(公益)”,是一个值得仔细研究的问题。
(一)人工智能生成的内容能否适用知产法保护
1、HIGC v.s. AIGC
从生成的来源上看,本文将生成的内容分为两类:AIGC(Artificial Intelligence Generating Contentn,AIGC)与HIGC(Human Intelligence Generating Content),二者具体分类如下:
HIGC:包括UGC(User Generating Content)、OGC(Organization Generating Content)、PGC(Professional Generating Content)、PUGC等
AIGC包括:ChatGPT、BERT、Stable Diffusion、Midjourney、DALL.E、文心一言、通义千问等、ChatGLM等。
HIGC输出是人的智力创造活动,创作的结果受知识产权法保护,典型的就是受著作权法保护,当然,也可能受专利保护。注意,HIGC创作的过程是事实行为,但是创作的意图则是有法律意义的行为,即:作者有创作的意思,因之其属于法律行为,受法律保护。
AIGC的输出显然不是人的智力创造活动,如前原理部分所示,AIGC的输出,只不过是一个函数的运算结果输出,用算式表达可以表达为:Output=f(Prompt),Output是一种结构的输出数据,它可以是一段文字,可以是一段声音,可以是一幅图片等 ,Prompt是用户用自然语言描述的输入,f则是那个生成式的函数,生成的内容(输出的数据)显然与人的意思无关,这些内容的生成本质是AI-System这套软件系统通过检索、集中模型(Model,经过训练而产生的)的知识(素材)通过一定的技术处理而合成后形成的一个字节序列,显然AIGC输出的内容不是人的智力创作行为,而且人类也无法控制AI-System具体生成的过程,整个AIGC的过程完全不体现人的意志。尽管人可以通过自然语言表达生成的要求,但是究竟生成什么样的内容取决于AI-System的模型。再者,AI-System的输出是一个随机化的序列输出,因为在同一AI-System上,同样的输出,会产生不同的输出,比如,在DALL.E上,输入一句话“画一个苹果图片”,反复输入同样的一句话,会产生不同的输出,同样道理,在chaGPT上,同样一句问题反复输入,会产生不同的输出,这充分证明AIGC输出的内容是一种随机输出的数据序列,这显然与HIGC是完全不同的。
2、AIGC的输出内容不适用包括版权法在内的知识产权法保护。
不论是从世界上第一部分著作权法/版权法《安娜法令》看还是从当今世界各国的著作权法/版权法,知识产权法保护的都是人的创作行为,即人通过自己的智力创作行为形成作品,这种作品受法律保护,保护的最直接效果体现为在一定时期内对收益权的独占性。类似的现象在专利领域也存在,这种立法的目的是鼓励人发挥自己的智慧创造力。同时也体现了公平原则,即:人人都可能基于自身的智慧、努力来创作作品。
显然,AIGC在以上两个方面均不满足条件,具体而言:第一,AIGC产生的内容输出,不是人的智力创作成果,它是机器的输出,不受著作权法/版权法保护。中国《著作权法》中将作品明确定义为“智力成果”,德国《著作权及邻接权法》中使用德语“Werk”这个单词表达“作品”,美国《美国版权法》中使用英语单词“work”,两者都是指代“人的工作”,从立法用语上看,就能体现出来,版权法/著作权法要求作品是人的智力输出。机器的随机序列输出显然不满足条件。第二,人类的创作行为本质上是属于人的社会活动之一,带有社会属性,它不属于商事行为,而AIGC是基于AI-System中经训练产生的模型而生成新内容,训练AI-System和利用AI-System生成内容,显然都属于具体的商事行为,不属于普通的社会活动,完全没有社会属性。这与知识产权类立法的立法宗旨完全背离。第三,利用AI-System生成内容也不属于委托创作,因为委托关系只能发生在人与人之间,不可能发生在人与机器之间,尽管人类是通过人类语言给AI-System下达指令,令其生指定要求的新内容,但是显然不是委托关系,也不是任何合同关系,而是事实行为,属于对软件功能的具体操作。
显然,无论是著作权还是专利权,保护的都是人的智力创作成果,这种创作成果是基于人的知识、情感、履历等方面因素综合影响而形成的,这是AIGC所不具备的最本质的特征。
因此,AIGC产生的新内容,显然不受包括版权法/著作权法在内的知识产权立法保护。
3、AIGC输出的内容应当如何保护?
AIGC生成的内容虽然不适合用知识产权法保护,但是其仍然具备保护的必要性。
有观点认为,AIGC可以作为商业秘密保护,这一观点显然并不合适,因为商业秘密需要保密,一般不会对外公示,否则无法称为商业秘密,而AIGC的内容显然不满足这个条件,它通常很容易也必然被外界知晓。
本文认为,可以应当从物权及资产理论的角度出发,建立数字资产(Digital Asset)/数据资产(Data Asset)制度,具体包括数字资产的确权、认证、转让等制度,即,将数据资产、物权化。一旦数据可以资产化之后,则AIGC生成的内容自然可以作为数字资产,因为不论AI-System输出的是文字、声音、图片等 ,其都是一段独立可存储的数据。
具体而言,首先,AIGC生成的内容(数据)有商业价值(包括使用价值和交换价值),可以通过技术手段被人有效的占有、使用、收益、处分,因而可以作为所有权的客体而存在,自然也就可以资产存在;其次,AIGC生成的内容作为数字资产/数据资产,其本质上是AI-System生产出的产品,用户为得到这类产品通常事先支付了对价(比如购买某个AI-System的帐号或是自行搭建训练AI-System),用户之所以愿意支付对价,显然是因为AIGC能给企业或个人带来现实利益,这使得其具备会计学意义上资产的属性。最后,随着Web3概念的流行,数据作为资产已经不再陌生,Web3的核心是“数据所有权”的问题,即:谁生产的数据属于谁所有、该数据产生收益如何合理分配的问题。有关于这方面将在另外的文章详述。
二、总结
人工智能系统在训练与生成内容的过程中,以上三个法律问题是必须解决的,最关键的问题,而且须体系化解决,由于AI-System作为一种新生事物,与传统的计算机信息系统有质的区别,所以传统理论显然并不能全面解决AI-System带来一些新问题,需要进行理论和制度创新,以便更好地利用人工智能系统,服务于生产、生活。







